2014年,Google提出了Sequence-to-Sequence模型,旨在将句子文本映射到fixed-length向量,其中输入和输出的长度可能会有所不同。Seq2Seq通常应用于NLP领域的文本生成任务,例如摘要生成、语法纠错、句子合并等。
尽管最新的研究突得端到端的方法在文本生成上比之前更有优势,但其本身存在的不可解释性,一方面使得该模型需要大量的训练数据才能达到可接受的性能水平,另一方面通常只能逐字生成文字,本质上是很慢的。
近日,Google研究团队开源了一款文本编辑模型LaserTagger,可推理出一系列编辑操作,以将源文本转换为目标文本。研究人员断言,LaserTagger处理文本生成一般不易出错,且更易于训练和执行。
在此之前,Google已经发布了Meena,一个具有26亿个参数的神经网络,可处理多轮对话。1月初,Google在论文中还提出了Reformer模型,可处理所有小说。
GitHub链接:https://github.com/google-research/lasertagger
LaserTagger设计和功能
对于许多文本生成任务,输入和输出之间存在高度重叠,LaserTagger正是利用了一点。例如,在检测和纠正语法错误或多个合并句子时,大多数输入文本可以保持不变,只需修改一小部分单词。然后,LaserTagger会生成一系列编辑操作,而非实际单词。
目前支持的四种编辑操作:
Keep(将单词复制到输出中)
Delete(删除单词)
Keep-AddX(添加短语X到标记的单词前)
Delete-AddX(删除标记的单词)
下图对LaserTagger在句子合并中的应用进行了说明。
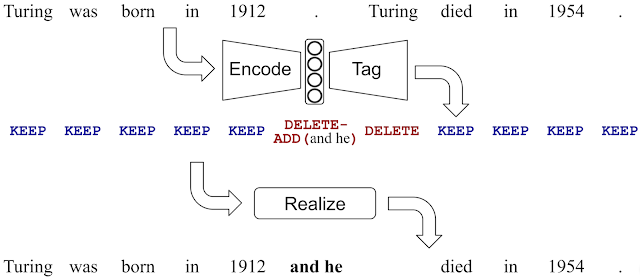
图注:LaserTagger预测的编辑操作中,删除“Turing”,添加“ and he ”。请注意,输入和输出文本存在的高度重叠。
所有添加的短语均来自受限制的词汇表。该词汇表是一个优化过程的结果,该优化过程具有两个目标:(1)最小化词汇表的大小和(2)最大化训练样本的数量,其中添加到目标文本的唯一必要单词仅来自词汇表。短语词汇量受限制会使输出决策的空间变小,并防止模型添加任意词,从而减轻了“幻觉”(注:hallucination,模型在所生成的文本中,输入信息中并不存在)的问题。
输入和输出文本的高重叠性的一个推论是,所需的修改往往是局部的并且彼此独立。这意味着编辑操作可以高精度地并行推理,与顺序执行推理的自回归seq2seq模型相比,可显著提高端到端的速度。
结果
研究人员评估了LaserTagger在四个任务中的表现,分别是:句子合并,拆分和改述,抽象总结和语法纠正。结果显示,使用大量训练样本情况下,LaserTagger与基于BERT的seq2seq基线成绩相当,并且在训练样本数量有限时明显优于基线。下面显示了WikiSplit数据集上的结果,其中的任务是将一个长句子改写为两个连贯的短句子。
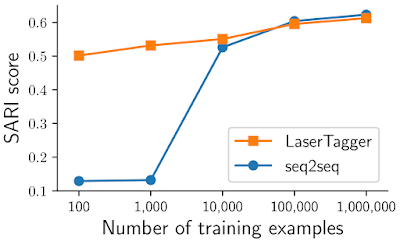
图注:在100万个样本的完整数据集上训练模型时,LaserTagger和基于BERT的seq2seq基线成绩相当,但在10,000个或更少样本的子样本上进行训练时,LaserTagger明显优于基线模型(SARI得分越高越好)。
LaserTagger主要优点
与传统的seq2seq方法相比,LaserTagger具有以下优点:
控制:通过控制输出短语词汇(也可以手动编辑或整理),LaserTagger比seq2seq基线更不易产生“幻觉”问题。
推理速度:LaserTagger计算推理的速度比seq2seq基线快100倍,能够满足实际情况下的实时问题。
数据效率:即使仅使用几百或几千个训练样本进行训练,LaserTagger也会产生合理的输出。实验中,seq2seq基线需要成千上万个样本才能获得相同的性能。
Google团队最后写道:“ LaserTagger的优势在大规模应用时变得更加明显,例如,通过缩短响应时间并减少重复性,改进了某些服务中语音应答的格式。高推理速度使该模型可以插入现有技术堆栈中,而不会在用户端增加任何明显的延迟,而改进的数据效率可以收集多种语言的训练数据,从而使来自不同语言背景的用户受益。 ”
相关链接:https://ai.googleblog.com/2020/01/encode-tag-and-realize-controllable-and.html